
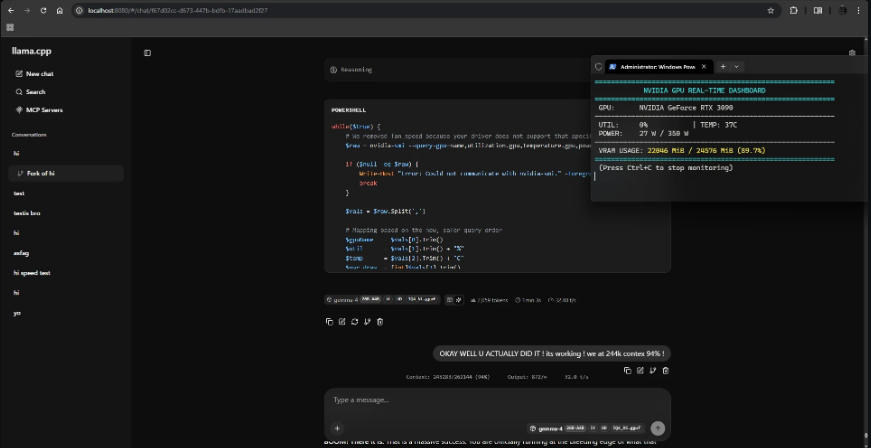
عندما أطلقت Google نموذج Gemma 4 بنسخته التي تحتوي على 26 مليار معلمة، كان الانطباع الأول لدى أغلب المستخدمين:
"هذا رائع، لكن حاسوبي لن يستطيع تشغيله أبداً!"
منطقياً، النماذج بهذا الحجم تتطلب ذاكرة وصول عشوائي وبطاقات رسوميات بأسعار فلكية. لكن Gemma 4 26B يختلف عن كل النماذج السابقة — لأن وراءه سرّان مزدوجان جعلا تشغيله ممكناً على حواسيب عادية.
في هذا المقال سنكشف لك هذين السرين، ونأخذك في خطوات بسيطة لتثبيت النموذج وتجربته بنفسك.
السر الأول: Mixture of Experts — العبقرية المعمارية
قبل أن نتحدث عن الضغط، يجب أن تفهم ما يجعل Gemma 4 26B مختلفاً جوهرياً عن أي نموذج 26B آخر.
Gemma 4 26B ليس نموذجاً تقليدياً — بل هو نموذج Mixture of Experts (MoE)، ومعناه ببساطة :
تخيل أن لديك فريقاً من 26 خبيراً متخصصاً. عندما تطرح سؤالاً، لا يجيب عليك الفريق كله — بل يختار النظام تلقائياً أذكى 3-4 خبراء فقط المناسبين لسؤالك، ويتجاهل الباقين.
هذا بالضبط ما يفعله Gemma 4 26B:
- إجمالي المعلمات: 26 مليار — تُخزّن في الذاكرة
- المعلمات النشطة في كل استجابة: 3.8 مليار فقط
- النتيجة: سرعة نموذج صغير + ذكاء نموذج ضخم
هذا وحده يقلّص متطلبات الحوسبة بشكل هائل. لكن المشكلة الباقية هي حجم التخزين والذاكرة — وهنا يدخل السر الثاني.
السر الثاني: تقنية 4-bit Quantization
حتى مع MoE، لا يزال تخزين 26 مليار معلمة يحتاج مساحة ضخمة. هنا تأتي تقنية الضغط (Quantization).
لتبسيط الأمر: تخيل صورة بدقة 4K عالية — حجمها كبير وتحتاج شاشة متطورة. إذا ضغطتها إلى 1080p، يقل حجمها بشكل كبير، لكن التفاصيل الأساسية تبقى واضحة للمشاهد العادي.
هذا ما تفعله تقنية Quantization:
- النموذج الأصلي بصيغة 16-bit = ضخم جداً
- بعد الضغط إلى 4-bit = يتقلص الحجم بنسبة 75%
- يُحفظ بصيغة GGUF وهو الصيغة المناسبة للتشغيل المحلي
السحر يحدث عند دمج السرّين معاً
| الحالة | الذاكرة المطلوبة |
Gemma 4 26B بدون أي ضغط (16-bit) الذاكرة المطلوبة : ~52 GB مع MoE فقط (8-bit) الذاكرة المطلوبة : ~28 GB مع MoE + ضغط 4-bit الذاكرة المطلوبة : 18 GB فقط
من 52GB إلى 18GB — بدون خسارة ملحوظة في الذكاء.
هل يفقد Gemma 4 ذكاءه بعد الضغط؟
هذا السؤال الأهم. التجارب الميدانية من مجتمع r/LocalLLaMA ومختبرات Unsloth أثبتت :
خسارة الذكاء بعد الضغط إلى 4-bit لا تتجاوز 5% — وهي غير ملحوظة عملياً للمستخدم العادي.
النموذج بعد الضغط لا يزال قادراً على:
- التفكير المنطقي المعقد — يحل الألغاز ويفهم السياق الطويل حتى 256K token
- البرمجة المتقدمة — يكتب ويصحح الأكواد بكفاءة عالية
- الفهم متعدد اللغات — يدعم أكثر من 140 لغة بما فيها العربية
- تحليل الصور — يفهم ويحلل المحتوى المرئي
وصل Gemma 4 26B إلى المرتبة السادسة عالمياً في تصنيف LMArena للنماذج المفتوحة — متفوقاً على نماذج أكبر منه بـ 20 ضعفاً في الحجم.
مقارنة سريعة: أي نسخة تختار؟
Gemma 4 E4B : الذاكرة المطلوبة : 8 GB+ سرعة الاستجابة : سريع جدا الذكاء والمنطق : ممتاز للمهام الأساسية دعم الصور والصوت : نعم **الاستخدام الموصى به : ** الحواسيب الاقتصادية والهواتف
Gemma 4 26B (4-bit) : الذاكرة المطلوبة : 24 GB+ سرعة الاستجابة : جيدة (تعتمد على المعالج) الذكاء والمنطق : أداء متقدم في البرمجة والتحليل المعقد دعم الصور والصوت : صور فقط **الاستخدام الموصى به : ** الحواسيب المتوسطة والقوية
متطلبات التشغيل الدقيقة لـ Gemma 4 26B
الحد الأدنى للتشغيل:
- RAM: 18 GB على الأقل (لنسخة 4-bit)
- مساحة تخزين: 20 GB فأكثر
- نظام التشغيل: Windows، Mac، أو Linux
للأداء الأفضل:
- GPU بـ VRAM 24 GB (مثل RTX 4090 أو RTX 3090)
- أو Mac M1/M2/M3 بذاكرة موحدة 24 GB فأكثر
ملاحظة مهمة: إذا كان جهازك يملك أقل من 18 GB — استخدم Gemma 4 E4B التي تعمل بـ 8 GB فقط وهي ممتازة للمهام اليومية.
طريقة التثبيت الكاملة
الطريقة الأولى: LM Studio (للمبتدئين — واجهة رسومية)
1. حمّل وثبّت LM Studio مجاناً
2. افتح البرنامج واذهب لتبويب البحث — اكتب:
Gemma-4-26B GGUF
3. اختر النسخة التي تنتهي بـ Q4_K_M — هي الأفضل من حيث التوازن بين الحجم والجودة
4. اضغط Download وانتظر انتهاء التحميل
5. اختر النموذج من قائمة الدردشة وابدأ المحادثة مباشرة
الطريقة الثانية: Ollama
1. حمّل وثبّت Ollama مجاناً
2. افتح Terminal أو Command Prompt واكتب:
ollama run gemma4:26b
3. انتظر انتهاء التحميل — ثم ابدأ المحادثة مباشرة في الطرفية
للتشغيل في المرات القادمة بدون إعادة التحميل:
ollama run gemma4:26b
الخلاصة
Gemma 4 26B يمثل نقلة نوعية حقيقية في عالم النماذج المفتوحة — ليس لأنه ضُغط فقط، بل لأنه مُصمَّم من الأساس ليكون فعالاً على الأجهزة الشخصية بفضل معمارية MoE المذهلة. حوّل نموذجاً يحتاج 52 GB إلى نموذج يعمل على 18 GB — مع الحفاظ على 95% من ذكائه الأصلي.
إذا كان جهازك يملك 18 GB RAM فأكثر — Gemma 4 26B هو أفضل نموذج مفتوح المصدر يمكنك تشغيله محلياً اليوم.
هل تريد التأكد أن النموذج سيعمل على جهازك قبل تحميله؟ → كيف تتأكد أن نموذج LLM سيعمل على جهازك قبل تحميله
هل تريد معرفة طريقة تحميل أي مشروع من GitHub بنقرة واحدة بدون Terminal أو Git 2026؟ → تحميل أي مشروع من GitHub بنقرة واحدة


